Web scraping et templating en Python
- Web scraping et templating en Python
Le but de ce TP est d’utiliser la bibliothèque Python requests-html qui permet de télécharger des documents HTML, de les analyser et de les parcourir, comme le fait en fait un navigateur, mais sans faire de rendu. Une partie du TP est consacré au rendu avec Jinja.
Introduction
Changelog
- 2022-08-31 : modification : rendre le template et la CSS
- 2022-08-29 : modification : template ligne 56,
columns.insert(3, "Description")remplacecolumns += ["Description"]
But du TP
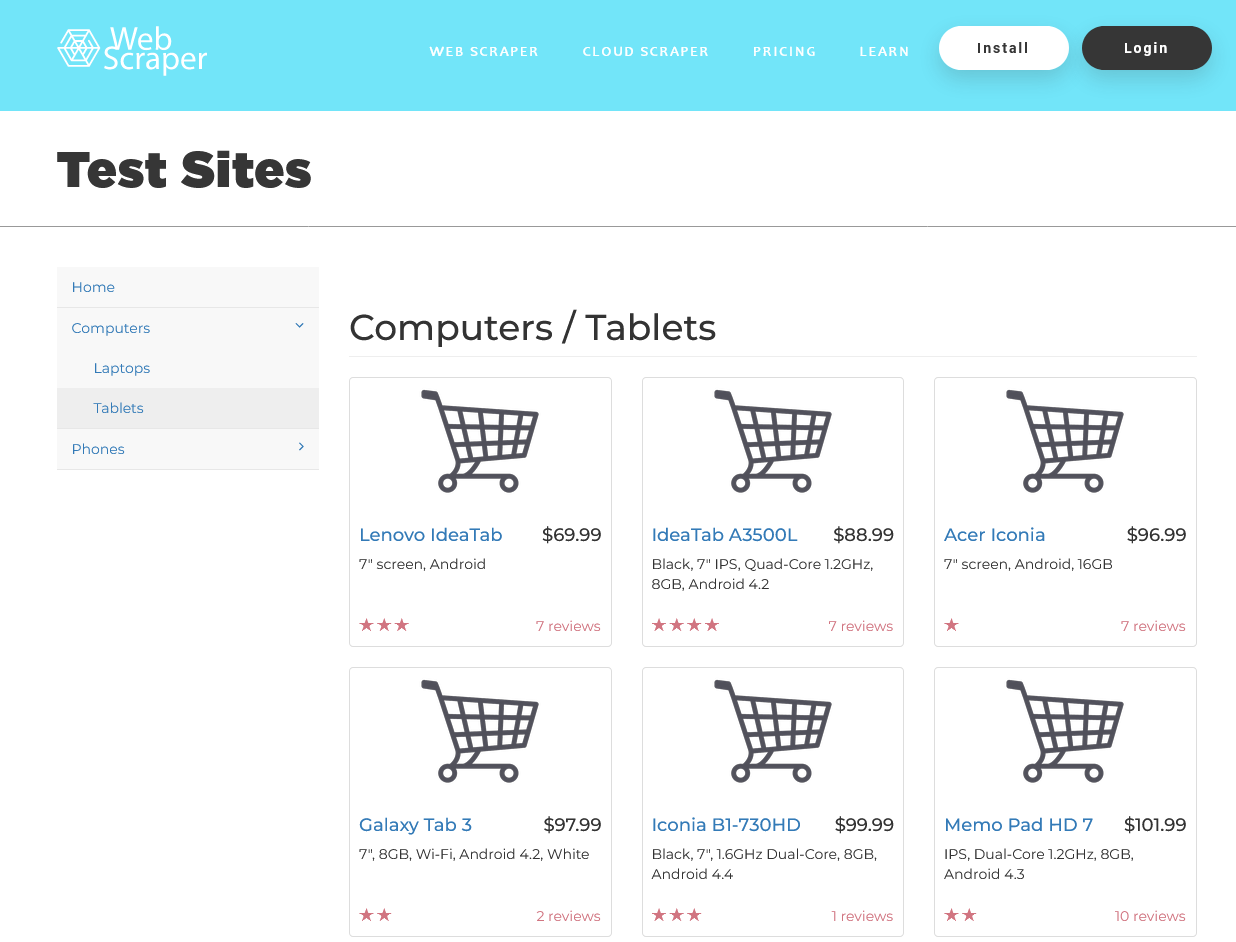
On va considérer le site https://webscraper.io/test-sites/e-commerce/allinone dont on donne une capture ci-dessous :
 .
.
Le but du TP est de faire un programme qui analyse ce site pour en extraire tous les produits vendus sous forme de feuille de calcul et sous forme de tableau HTML.
Remarques
Dans ce TP vous allez rencontrer des difficultés purement techniques liées à la maîtrise de Python et l’utilisation de bibliothèques. Vous aurez également à lire les documentations des bibliothèques utilisées comme :
- https://requests.readthedocs.io/projects/requests-html/en/latest/
- https://pandas.pydata.org/docs/reference/io.html et https://pandas.pydata.org/docs/user_guide/io.html
- https://jinja.palletsprojects.com/en/3.0.x/
Conseils :
- utiliser les f-strings (voir Real Python, python.org) pour un code plus concis et plus clair.
- utiliser les listes en compréhension (voir Real Python, python.org) pour un code plus concis et plus clair.
- utiliser une module de logging au lieu des simples
printpour suivre l’exécution et contrôler la verbosité des messages, utiliser pour cela le module standard logging Logging facility for Python, voir notamment Logging HOWTO. Un exemple de trace obtenue avec le moduleloggingest donné en annexe.
Installation
Tout d’abord, créer un dossier de travail webihm-tp5/ et installer les modules Python avec les commandes suivantes, où python est votre exécutable de Python (qui peut être python3, python.exe ou python3.9 selon la plate-forme utilisée) :
# pour mettre à jour pip
python -m pip install --upgrade pip
# pour installer les dépendances de ce projet
python -m pip install requests_html pandas Jinja2
Par exemple, en salle F2, les commandes sont les suivantes
& "C:/Program Files/Python39/python.exe" -m pip install --upgrade pip
& "C:/Program Files/Python39/python.exe" -m pip install requests_html pandas Jinja2
Ensuite télécharger dans le dossier webihm-tp5/ :
- le tutoriel tutorial.py;
- le fichier de départ scraper.py à compléter.
Rendu
Le TP est à rendre sur https://foad.unc.nc/ pour au plus tard le mardi 6 septembre à 23h59.
Il faut rendre uniquement les fichiers scraper.py complété (pas le tutoriel), le template table.jinja2.html et la CSS table.css.
Les critères d’évaluation sont les suivants :
- les fonctionnalités de l’application
- recherche des catégories et sous-catégories
- collecte et agrégation des produits des sous-catégories
- sauvegarde sous forme de feuille de calcul
.csv - rendu HTML des produits avec Jinja
- styles CSS pour le tableau précédent
- collecte des informations détaillées des produits
- collecte précédente asynchrone
- la qualité du code
La correction étant en partie automatisée, il faut impérativement respecter les structure de données attendues.
Prise en main
Cette première partie n’est pas à rendre mais il est nécessaire de la réaliser avant de passer à la suite.
- Exécuter le programme tutorial.py, noter ce qui s’affiche.
- Afficher le champs
Serverde l’en-tête HTTP de l’objetresponse(documentation), noter ce qui s’affiche. - Afficher le contenu de la page https://python.org sur la console.
Avec la méthode find(selector, first=bool) de la classe HTMLElement, on peut utiliser les sélecteurs CSS pour faire une requête sur un élément HTML. find(selector, first=True) retournera le premier élément HTML ou None tandis que find(selector, first=False) renverra une liste d’éléments HTML.
- Exécuter
response.html.find('a', first=False)puis parcourir la liste avec un bouclefor ... in ...:pour afficher tous les attributshref, accessible viaelement.attrs["href"]- Expliquer en termes simples ce que fait le code précédent
- Modifier le sélecteur CSS pour garder uniquement les liens qui commencent par
http(il devrait y en avoir 66)
- Trouver l’adresse de l’image du logo de Python avec la classe CSS
python-logo. - Lancer le téléchargement du logo et enregistrer le contenu de l’image (attribut
contentdeHTMLResponse) avec le code suivant.
with open("python-logo.png", 'wb') as file:
file.write(contenu_a_écrire)
Identification des catégories et des sous-catégories
Désormais, tout se passe dans le fichier scraper.py à compléter.
La première étape consiste à analyser la page d’accueil pour en extraire lle premier niveau hiérarchique de la classification des produits, les catégories. On donne un extrait ci dessous du menu, avec les deux catégories Computers et Phones :
<div class="col-md-3 sidebar">
<div class="navbar-default sidebar" role="navigation">
<div class="sidebar-nav navbar-collapse">
<ul class="nav" id="side-menu">
<li class="active">
<a href="/test-sites/e-commerce/allinone">Home</a>
</li>
<li>
<a href="/test-sites/e-commerce/allinone/computers" class="category-link">
Computers
<span class="fa arrow"></span>
</a>
</li>
<li>
<a href="/test-sites/e-commerce/allinone/phones" class="category-link">
Phones
<span class="fa arrow"></span>
</a>
</li>
</ul>
</div>
</div>
</div>
Travail à faire: collect_subcategories()
Compléter collect_subcategories() pour extraire les noms et les liens complets des catégories à l’aide de la méthode HTML.find() et d’un sélecteur CSS bien choisi. Utiliser HTML.attrs pour accéder aux attributs des éléments HTML et à HTML.text pour le contenu textuel des balises. Ici, il faut bien choisir les sélecteurs CSS pour extraire l’information intéressante.
Analyse des sous-catégorie
Maintenant, pour chaque catégorie obtenue précédemment, il faut aller sur la page et en extraire le deuxième niveau de classification des produits. On voit par exemple que Computers a deux sous-catégories Laptops et Tablets :
<div class="col-md-3 sidebar">
<div class="navbar-default sidebar" role="navigation">
<div class="sidebar-nav navbar-collapse">
<ul class="nav" id="side-menu">
<li>
<a href="/test-sites/e-commerce/allinone">Home</a>
</li>
<li class="active">
<a href="/test-sites/e-commerce/allinone/computers" class="category-link active">
Computers
<span class="fa arrow"></span>
</a>
<ul class="nav nav-second-level collapse in">
<li>
<a href="/test-sites/e-commerce/allinone/computers/laptops" class="subcategory-link"> Laptops </a>
</li>
<li>
<a href="/test-sites/e-commerce/allinone/computers/tablets" class="subcategory-link"> Tablets </a>
</li>
</ul>
</li>
<li>
<a href="/test-sites/e-commerce/allinone/phones" class="category-link">
Phones
<span class="fa arrow"></span>
</a>
</li>
</ul>
</div>
</div>
</div>
Travail à faire: terminer collect_subcategories()
Reprendre collect_subcategories() pour visiter chaque catégories et en extraire les sous-catégories et leurs liens, le résultat attendu doit avoir la forme suivante, une liste de triplets contenant dans cet ordre l’URL, la catégorie et la sous-catégorie :
[('https://webscraper.io/test-sites/e-commerce/allinone/computers/laptops',
'Computers',
'Laptops'),
('https://webscraper.io/test-sites/e-commerce/allinone/computers/tablets',
'Computers',
'Tablets'),
('https://webscraper.io/test-sites/e-commerce/allinone/phones/touch',
'Phones',
'Touch')]
Identification des produits
Maintenant qu’on dispose de toutes les sous-catégories, on peut aller visiter les liens et en extraire tous les produits de la page. Un produit est représenté comme suit
<div class="thumbnail">
<img class="img-responsive" alt="item" src="/images/test-sites/e-commerce/items/cart2.png" />
<div class="caption">
<h4 class="pull-right price">$24.99</h4>
<h4>
<a href="/test-sites/e-commerce/allinone/product/486" class="title" title="Nokia 123">Nokia 123</a>
</h4>
<p class="description">7 day battery</p>
</div>
<div class="ratings">
<p class="pull-right">11 reviews</p>
<p data-rating="3">
<span class="glyphicon glyphicon-star"></span>
<span class="glyphicon glyphicon-star"></span>
<span class="glyphicon glyphicon-star"></span>
</p>
</div>
</div>
Travail à faire: scrap_subcategory() et scrap_all_products()
Compléter scrap_subcategory() pour extraire le nom, le lien, le prix et le lien de chaque produit d’une sous-catégorie donnée à l’aide de sélecteurs CSS. Le résultat attendu doit avoir une forme similaire à la suivante, ici pour les téléphones, noter qu’on fait figurer la catégorie et la sous-catégorie de chaque produit. Le résultat attendu doit avoir la forme suivante, une liste de sextuplets contenant dans cet ordre la catégorie, la sous-catégorie, le nom du produit, l’URL, le prix et le nombre d’étoiles :
[('Phones',
'Touch',
'Nokia 123',
'https://webscraper.io/test-sites/e-commerce/allinone/product/486',
'24.99',
'3'),
('Phones',
'Touch',
'LG Optimus',
'https://webscraper.io/test-sites/e-commerce/allinone/product/487',
'57.99',
'3'),
('Phones',
'Touch',
'Samsung Galaxy',
'https://webscraper.io/test-sites/e-commerce/allinone/product/488',
'93.99',
'3'),
('Phones',
'Touch',
'Nokia X',
'https://webscraper.io/test-sites/e-commerce/allinone/product/489',
'109.99',
'4'),
('Phones',
...
'Iphone',
'https://webscraper.io/test-sites/e-commerce/allinone/product/494',
'899.99',
'1')]
Ensuite, compléter scrap_all_products() qui va exécuter scrap_subcategory() pour chacune des sous-catgégories extraite par collect_subcategories(). On obtient ainsi 147 produits au total (vérifiez que vous obtenez bien le même nombre)
Rendu tabulaire
La bibliothèque https://pandas.pydata.org/ est incontournable pour la gestion des données tabulaires en Python.
Avec le constructeur DataFrame() charger le tableau produit par scrap_products() puis ensuite utiliser DataFrame.to_csv() pour les exporter au format csv
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_csv.html#pandas.DataFrame.to_csv
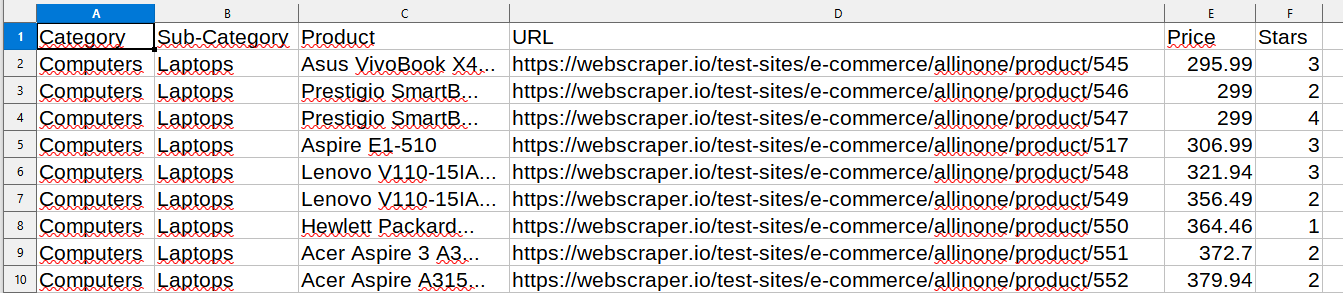
Le rendu final est une feuille de calcul (voir exemple) comme suit, ouverte ici avec https://www.libreoffice.org/discover/calc/ :
Travail à faire: save_spreadsheet()
Compléter save_spreadsheet() qui génère générer le fichier tabulaire comme products.csv contenant les informations des 147 produits scrapés sur le site.
Le résultat attendu doit respecter les noms et l’ordre des colonnes du fichier products.csv. Par contre, l’ordre des lignes ne compte pas.
Rendu HTML
Maintenant que l’on dispose de l’ensemble des produits sous forme de liste, on peut utiliser Jinja pour générer un rendu sous forme de tableau HTML avec un peu de mise en forme CSS.
NOTA BENE cette partie est indépendante des précédentes : vous pouvez la faire à partir du fichier products.csv fourni, même si vous ne l’avez pas créée vous même en scrapant le site.
Travail à faire: table.jinja2.html
La fonction save_html_table() est complète, il lui manque juste le template table.jinja2.html. Créez ce template et testez en appellant la fonction save_html_table().
Aidez-vous du CM6 - Web en Python et en particulier de ses exemples
Ensuite, définissez une feuille de style pour rendre le tableau agréable à utiliser. Utilisez les éléments des tableaux HTML (table, thead, tbody, tr, td, th) et les pseudo-classes :nth-child(An + b) pour alterner la couleur des lignes ou contrôler le positionnement dans les colonnes.
Le rendu final est une page HTML (voir exemple products.html) comme suit, ici avec un peu de CSS.
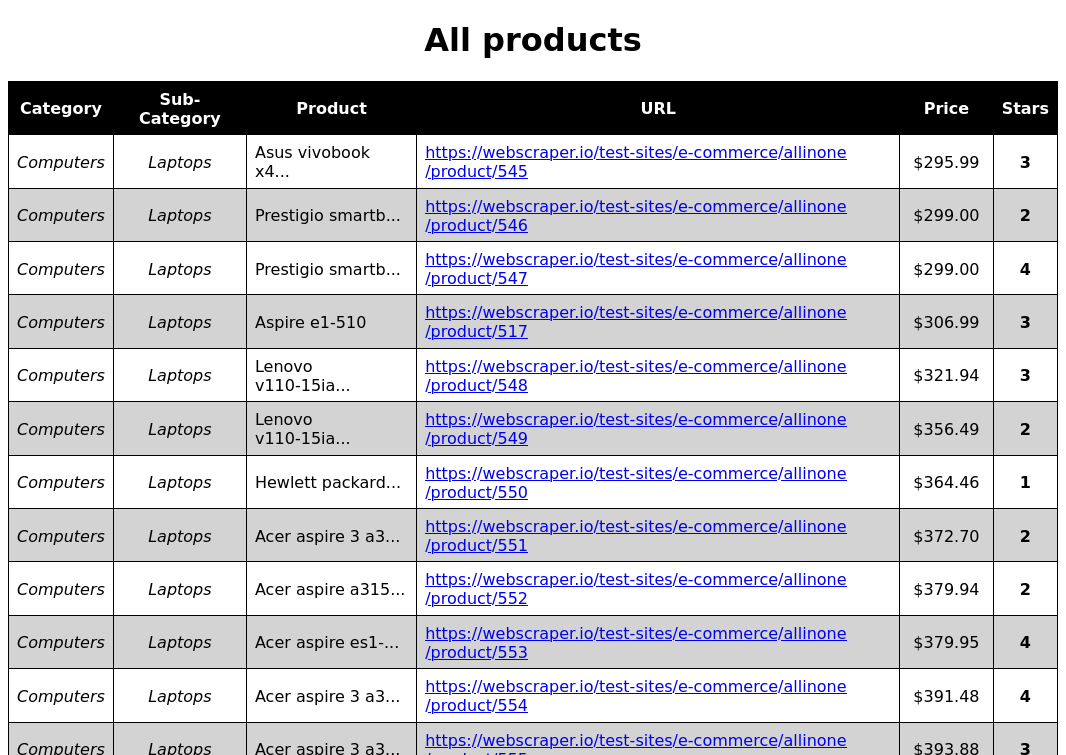
(*) Détails des produits
NOTA BENE la fin de cette partie est substantiellement plus difficile.
Avec la méthode précédente, certains noms de produits et description sont tronquées. Pour obtenir tous les détails, il faut visiter la page de chaque produit, on peut alors obtenir un fichier comme products_detailed.csv. On donner ci dessous un extrait de la fiche détaillée https://webscraper.io/test-sites/e-commerce/allinone/product/550.
<div class="thumbnail">
<div class="row">
<div class="col-lg-2">
<img class="img-responsive" alt="item" src="/images/test-sites/e-commerce/items/cart2.png" />
</div>
<div class="col-lg-10">
<div class="caption">
<h4 class="pull-right price">$384.46</h4>
<h4>Hewlett Packard 250 G6 Dark Ash Silver</h4>
<p class="description">
Hewlett Packard 250 G6 Dark Ash Silver, 15.6" HD, Celeron N3060 1.6GHz, 4GB, 128GB SSD, DOS
</p>
</div>
<label class="memory">HDD:</label>
<div class="swatches">
<button type="button" class="btn swatch" value="128">128</button>
<button type="button" class="btn swatch btn-primary" value="256">256</button>
<button type="button" class="btn swatch" value="512">512</button>
<button type="button" class="btn swatch disabled" value="1024">1024</button>
</div>
<div class="ratings">
<p>
12 reviews
<span class="glyphicon glyphicon-star"></span>
</p>
</div>
</div>
</div>
</div>
Travail à faire: scrap_details()
Compléter la fonction scrap_details() qui prend en paramètre le résultat de scrap_all_products() et intérroge la page de chaque produit pour obtenir les noms et descriptions complètes. Le résultat attendu doit avoir la structure suivante :
[('Computers',
'Laptops',
'Acer nitro 5 an515-51',
'Acer nitro 5 an515-51, 15.6" fhd ips, core i7-7700hq, 8gb, 256gb ssd +1tb, '
'geforce gtx 1050 ti 4gb, windows 10 home + windows 10 home',
'https://webscraper.io/test-sites/e-commerce/allinone/product/594',
'1140.62',
'3'),
('Phones',
'Touch',
'Iphone',
'Black',
'https://webscraper.io/test-sites/e-commerce/allinone/product/494',
'899.99',
'1'),
...
('Computers',
'Laptops',
'Acer aspire es1-572 black',
'Acer aspire es1-572 black, 15.6" hd, core i3-6006u, 4gb, 128gb ssd, windows '
'10 home',
'https://webscraper.io/test-sites/e-commerce/allinone/product/571',
'469.10',
'3')]
Générer le fichier tabulaire comme products_detailed.csv en adaptant save_spreadsheet() avec le paramètre detailed=True.
Ensuite, adapter le template Jinja pour qu’il gère la nouvelle colonne comme products_detailed.html
Travail à faire: scrap_details() version asynchrone
Le téléchargement des détails nécessite d’exécuter 147 requêtes, ce qui peut être un peu long si on exécute les requêtes les unes après les autres, en particulier s’il y avait plus de produits sur le site. Pour éviter cela, on peut exécuter des requêtes HTTP asynchrones en parallèle.
En vous inspirant de ce qui est fait dans async.py, reprennez le code de scrap_details() pour lancer les 147 requêtes en parallèle. Vous utiliserez pour cela la classe AsyncHTMLSession.
Annexe
trace d’exécution avec logging
DEBUG:SCRAPER:scrap_all_products: https://webscraper.io/test-sites/e-commerce/allinone
DEBUG:SCRAPER:collect_subcategories: https://webscraper.io/test-sites/e-commerce/allinone/computers
DEBUG:SCRAPER:scrap_subcategory: https://webscraper.io/test-sites/e-commerce/allinone/computers/laptops
DEBUG:SCRAPER:scrap_subcategory: https://webscraper.io/test-sites/e-commerce/allinone/computers/tablets
DEBUG:SCRAPER:collect_subcategories: https://webscraper.io/test-sites/e-commerce/allinone/phones
DEBUG:SCRAPER:scrap_subcategory: https://webscraper.io/test-sites/e-commerce/allinone/phones/touch
INFO:SCRAPER:save_spreadsheet: output/products.csv with 147 lines
INFO:SCRAPER:save_html_table: output/products.html
DEBUG:SCRAPER:scrap_details: https://webscraper.io/test-sites/e-commerce/allinone/product/545
...
DEBUG:SCRAPER:scrap_details: https://webscraper.io/test-sites/e-commerce/allinone/product/494
WARNING:urllib3.connectionpool:Connection pool is full, discarding connection: webscraper.io
WARNING:urllib3.connectionpool:Connection pool is full, discarding connection: webscraper.io
INFO:SCRAPER:save_spreadsheet: output/products_detailed.csv with 147 lines
INFO:SCRAPER:save_html_table: output/products_detailed.html